Diamond Pipeline
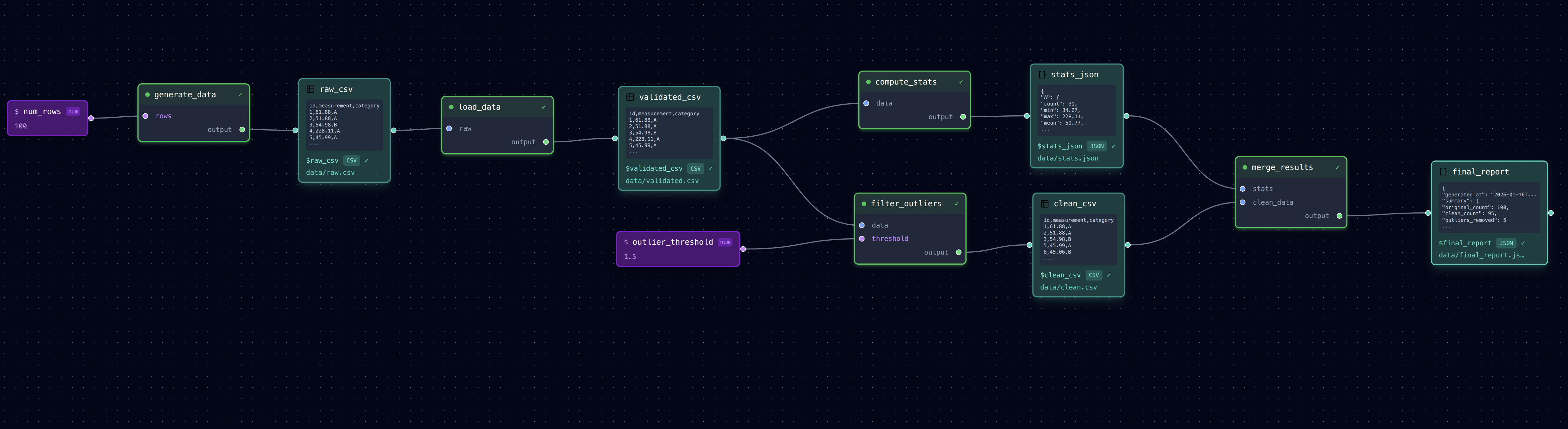
Branching and merging: one input feeds two parallel processing paths that combine at the end.
┌─► compute_stats ──► stats.json ───┐
load_data ──────┤ ├──► merge_results
└─► filter_outliers ──► clean.csv ──┘
What It Does
- load_data: Reads raw measurements and validates the format
- compute_stats: Calculates statistics on the raw data (parallel path A)
- filter_outliers: Removes outliers from the data (parallel path B)
- merge_results: Combines stats with cleaned data into a final report
This pattern is common when you need to both analyze and clean data, then combine the results.
Run It
# Full pipeline (parallel steps run in dependency order)
loom examples/diamond/pipeline.yml
# Check the outputs
cat examples/diamond/data/raw.csv # Input data
cat examples/diamond/data/validated.csv # After validation
cat examples/diamond/data/stats.json # Statistics (path A)
cat examples/diamond/data/clean.csv # Outliers removed (path B)
cat examples/diamond/data/final_report.json # Combined results
# Run from a specific step
loom examples/diamond/pipeline.yml --from filter_outliers
# Open in editor to see the diamond shape
loom-ui examples/diamond/pipeline.yml
Files
pipeline.yml— Pipeline configurationtasks/load_data.py— Validates and loads raw CSVtasks/compute_stats.py— Computes statisticstasks/filter_outliers.py— Removes outliers using IQR methodtasks/merge_results.py— Combines stats and clean datadata/raw.csv— Input data with some outliers